M
Meepo
2026年1月25日
语言模型
播客脚本
语音合成
TTS 音频
语音克隆
自定义音色
文生图
播客封面
效果演示
核心特点
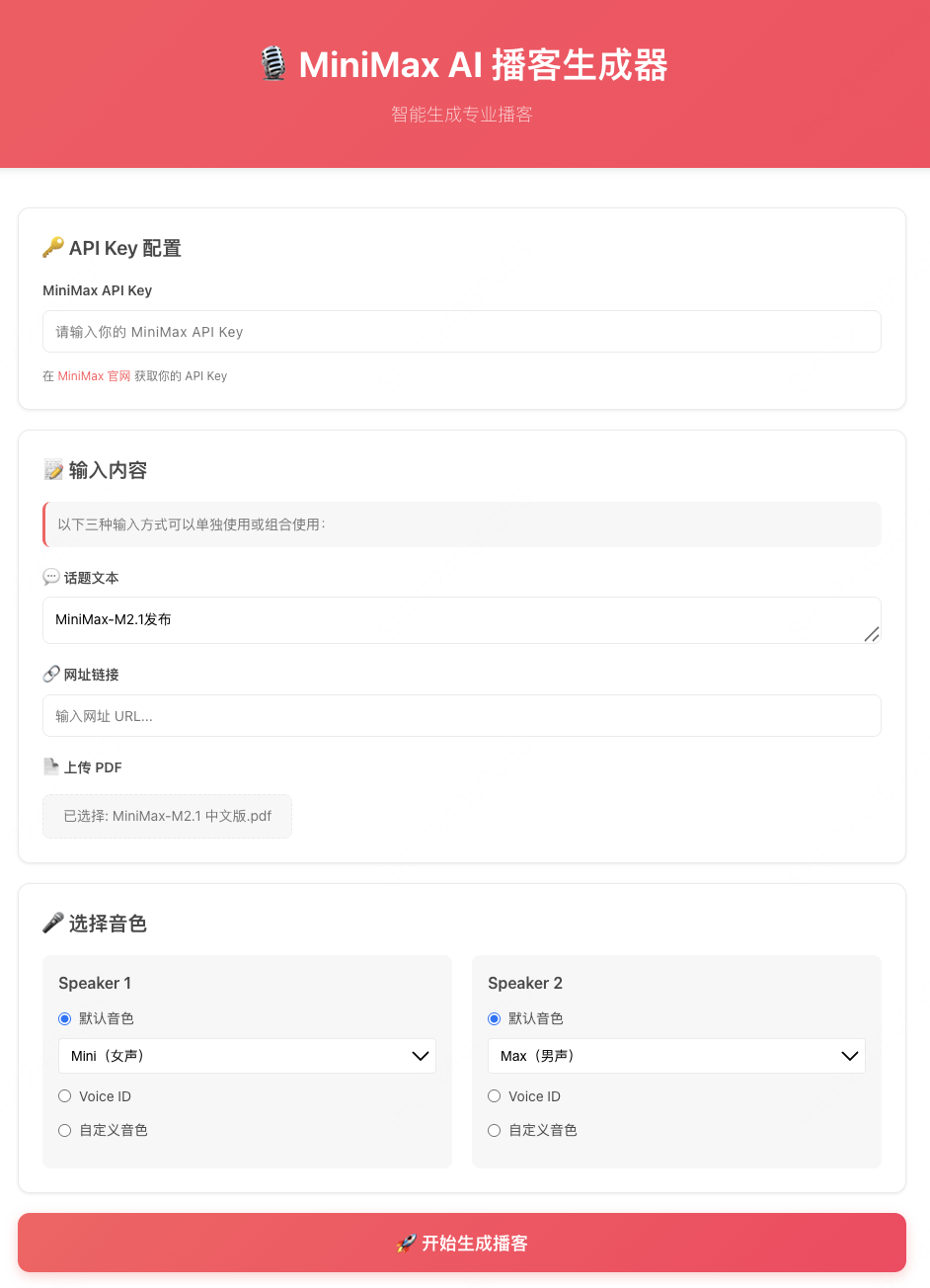
多种内容输入方式
多种内容输入方式
支持话题文本、URL、PDF 三种方式输入,基于 BeautifulSoup 和 PyPDF2 进行网页和 PDF 的解析,提取文本内容作为 LLM 生成播客内容的依据。
灵活的音色选择
灵活的音色选择
提供多种音色选择方案:使用预设的默认音色、输入 voice_id 选取自定义音色,或直接上传音频来复刻说话者的音色。
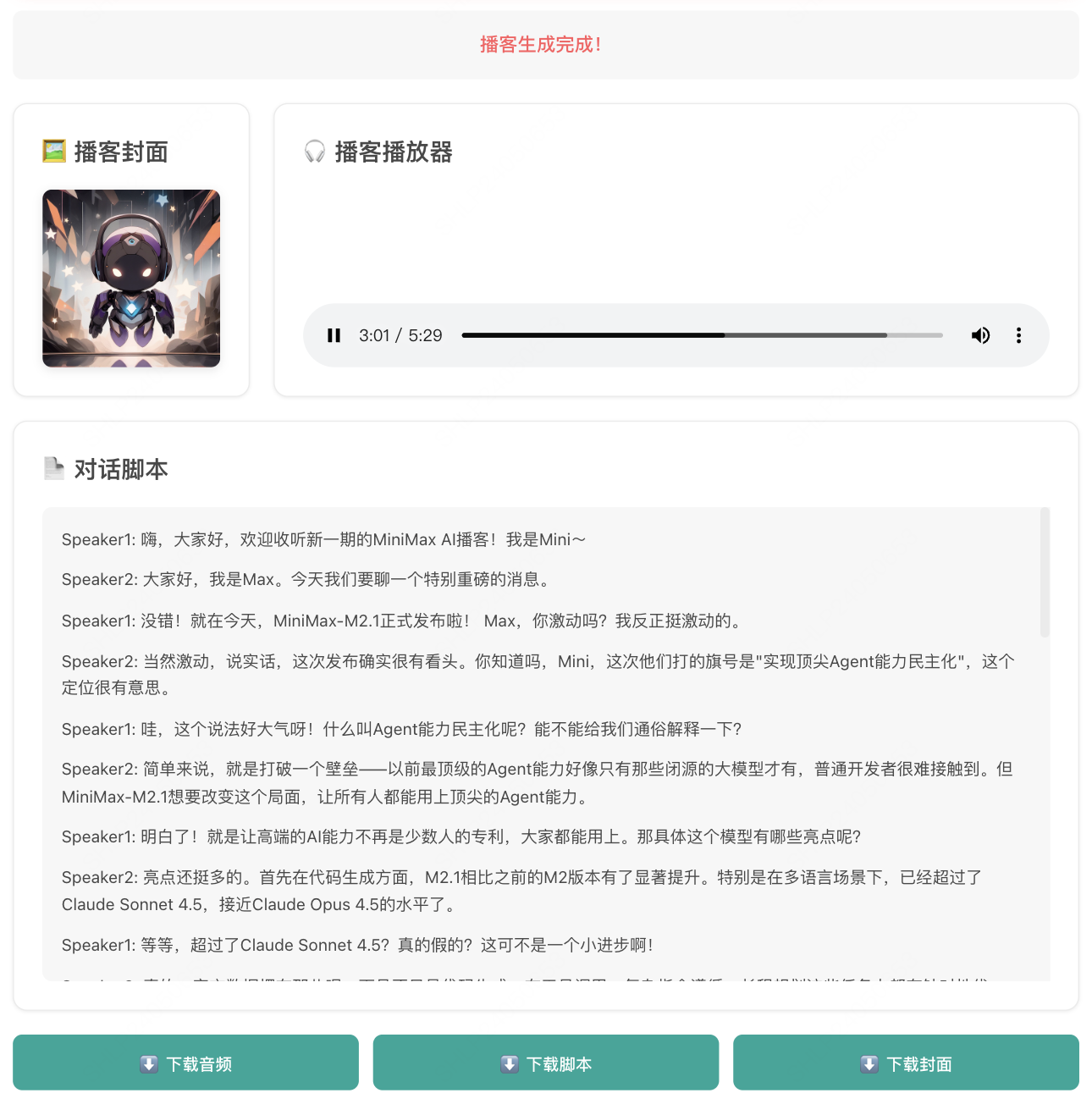
双主播对话生成
双主播对话生成
支持两个播音员角色,先分别生成各自的语句音频,再用 FFmpeg 将音频智能合并,形成自然的对话节奏。
自动生成播客封面
自动生成播客封面
先用语言模型基于播客内容生成封面图制作的 prompt,再用该 prompt 生成精美的播客封面图。
快速上手
核心 API 详解
- 语言模型
- 语音合成
- 语音克隆
- 文生图
实用技巧
| 场景 | 建议 |
|---|---|
| 音色试听 | 使用 语音调试台 试听并选择音色 |
| 模型选择 | speech-2.8-hd 自然度最高;speech-2.8-turbo 生成速度快 |
| 语音克隆 | 上传音频时长建议 15 秒左右,效果更佳 |
应用拓展
多角色播客
支持多角色灵活对话,无固定发言顺序
实时信息增强
加入搜索能力,提供最新消息
多语言播客
接入翻译能力,生成多语言版本
情感控制
利用情感参数,丰富表现力
总结
本教程展示了如何使用 MiniMax 多模态 AI 能力构建完整的 AI 播客生成应用。通过集成文本生成、TTS 语音合成、语音克隆、文生图四大核心能力,实现了从用户输入到播客成品的全流程自动化。 开发者可以基于本项目的架构思路,将 AI 能力组合成更多创新应用。相关资源
TTS API
语音合成接口
语音克隆
音色克隆接口
文生图
图像生成接口