> ## Documentation Index
> Fetch the complete documentation index at: https://platform.minimaxi.com/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# AI 播客生成:多模态 AI 应用实战
> 本教程将带您使用 MiniMax 语音模型 & 语言模型 构建一个完整的 AI 播客生成应用,实现从用户输入到播客成品的全流程自动化。
Download from GitHub
**AI 播客生成方案**通过集成 MiniMax 多模态模型,实现从用户输入需求到播客成品的**全流程自动化**。
👉 [在线体验](https://solution.minimaxi.com/minimax-aipodcast)
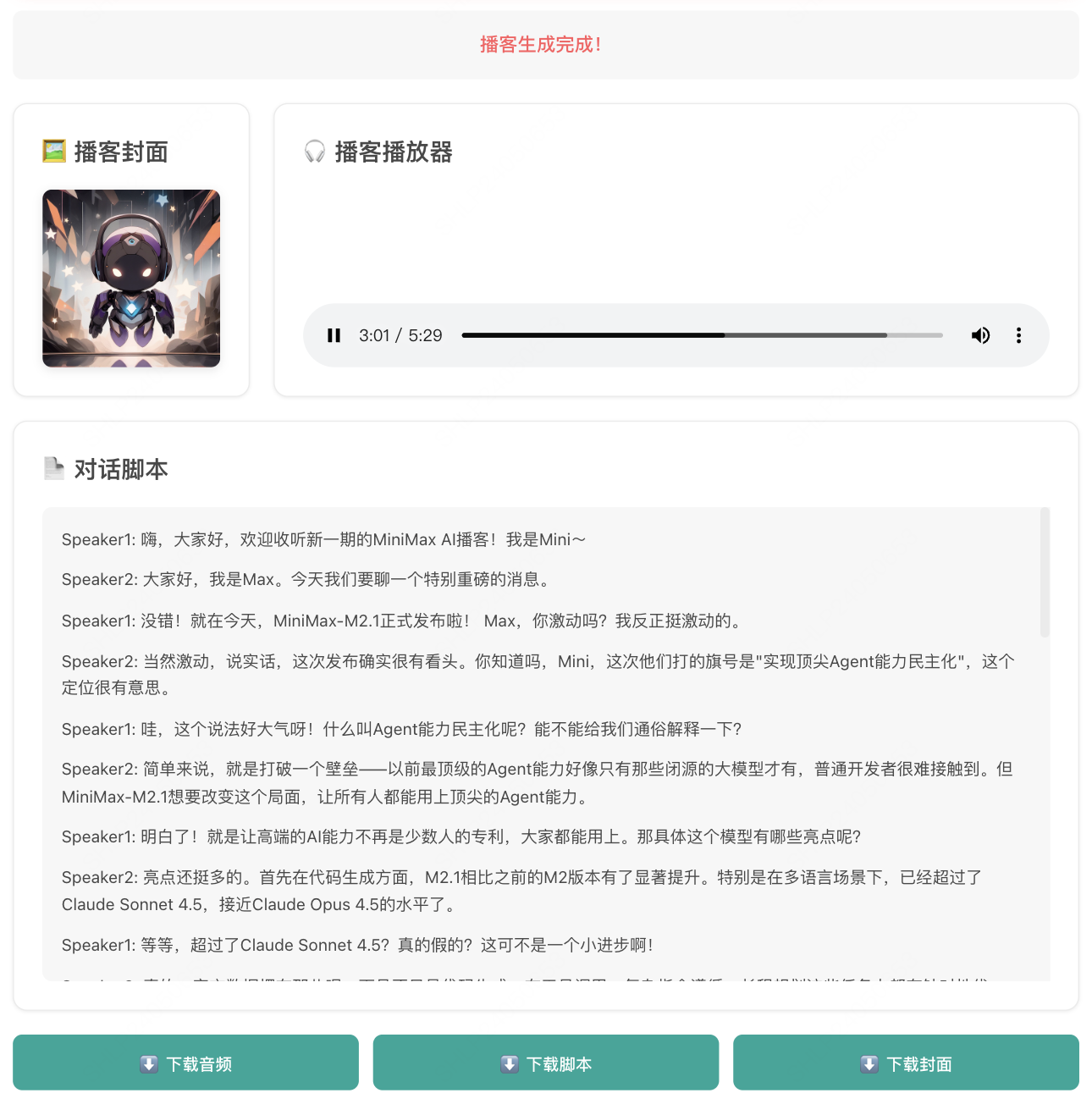
播客脚本
TTS 音频
自定义音色
播客封面
***
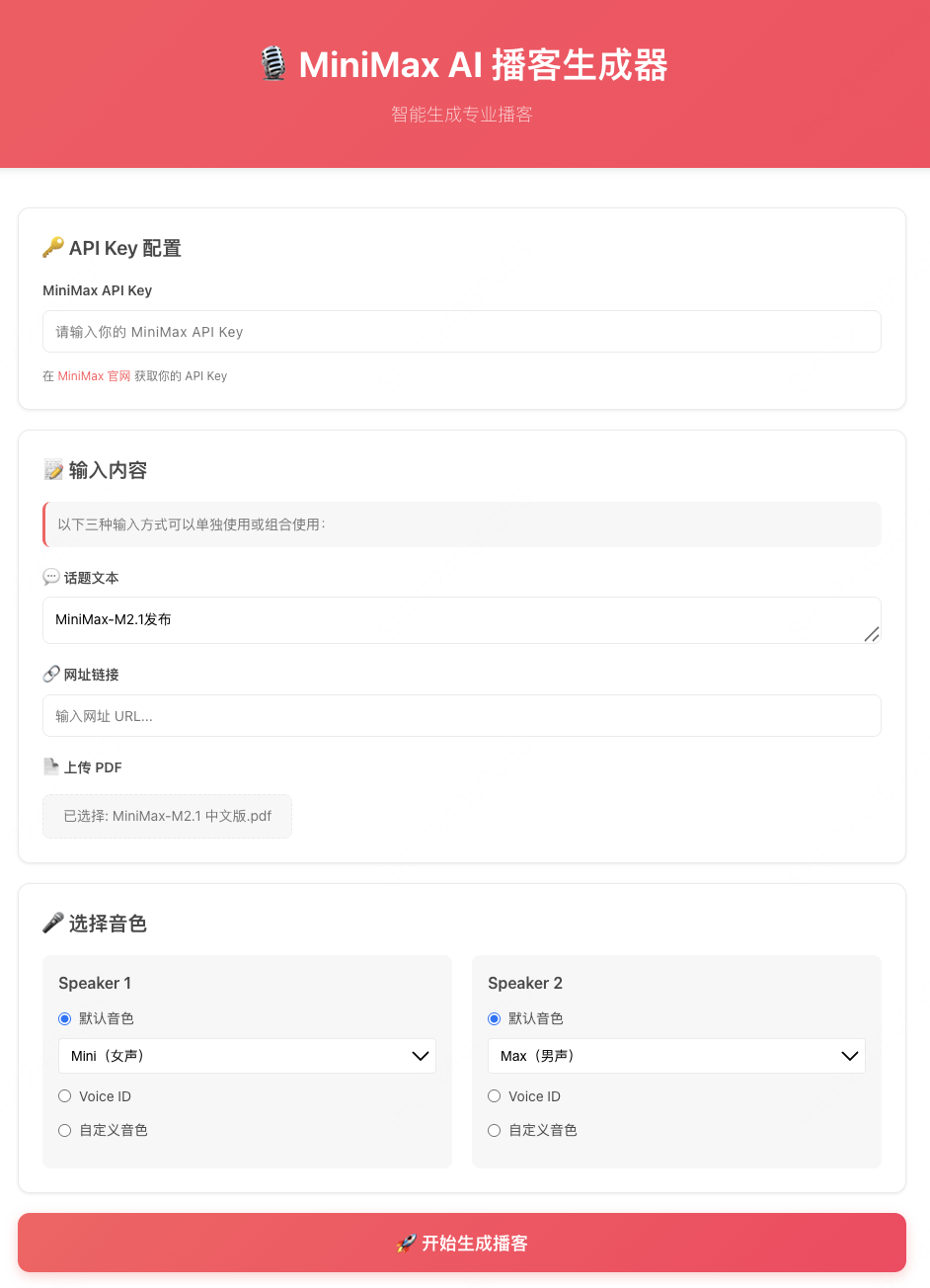
## 效果演示
***
## 核心特点
支持**话题文本、URL、PDF** 三种方式输入,基于 BeautifulSoup 和 PyPDF2 进行网页和 PDF 的解析,提取文本内容作为 LLM 生成播客内容的依据。
提供多种音色选择方案:使用预设的默认音色、输入 voice\_id 选取自定义音色,或直接上传音频来复刻说话者的音色。
支持两个播音员角色,先分别生成各自的语句音频,再用 FFmpeg 将音频智能合并,形成自然的对话节奏。
先用语言模型基于播客内容生成封面图制作的 prompt,再用该 prompt 生成精美的播客封面图。
***
## 快速上手
```bash theme={null}
git clone -b main https://github.com/MiniMax-OpenPlatform/minimax_aipodcast.git
cd minimax_aipodcast
```
**安装 FFmpeg**(用于音频处理):
```bash theme={null}
brew install ffmpeg
```
通过 [FFmpeg 官网](https://ffmpeg.org/download.html) 下载并安装
**安装项目依赖**:
```bash theme={null}
pip install -r requirements.txt
cd frontend && npm install
```
```bash theme={null}
chmod +x start.sh # 初次使用时执行
./start.sh
```
***
## 核心 API 详解
使用 MiniMax 语言模型生成播客内容脚本。
```python theme={null}
from openai import OpenAI
client = OpenAI(api_key=YOUR_API_KEY, base_url="https://api.minimaxi.com/v1")
response = client.chat.completions.create(
model="MiniMax-M2.1",
messages=[
{"role": "system", "content": "你是一个专业的播客脚本编写助手。"},
{"role": "user", "content": ""}
]
)
script = response.choices[0].message.content
```
建议使用 [OpenAI 兼容接口](/api-reference/text-openai-api) 或 [Anthropic 兼容接口](/api-reference/text-anthropic-api)。
使用 MiniMax Speech 2.8 模型生成播客音频。
```python theme={null}
import requests
response = requests.post(
"https://api.minimaxi.com/v1/t2a_v2",
headers={
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
},
json={
"model": "speech-2.8-hd",
"text": "您好,这是 MiniMax TTS 合成的语音。",
"stream": False,
"voice_setting": {
"voice_id": "Chinese (Mandarin)_Gentle_Senior",
"speed": 1,
"emotion": "happy"
},
"audio_setting": {
"sample_rate": 32000,
"format": "mp3"
}
}
)
audio_hex = response.json()["data"]["audio"]
```
| 参数 | 说明 |
| ---------- | ------------------------ |
| `model` | 推荐 `speech-2.8-hd` |
| `voice_id` | 系统预设或自定义音色 ID |
| `emotion` | 情感参数:happy, sad, angry 等 |
上传参考音频,创建自定义音色。
```python theme={null}
import requests
# Step 1: 上传复刻音频
upload_resp = requests.post(
"https://api.minimax.chat/v1/files/upload",
headers={"Authorization": "Bearer YOUR_API_KEY"},
files={'file': ('ref.wav', open('ref.wav', 'rb'), 'audio/wav')},
data={'purpose': 'voice_clone'}
)
file_id = upload_resp.json()["file"]["file_id"]
# Step 2: 克隆音色
clone_resp = requests.post(
"https://api.minimax.chat/v1/voice_clone",
headers={
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
},
json={
"file_id": file_id,
"voice_id": "my_custom_voice",
"model": "speech-02-turbo"
}
)
```
参考音频要求:清晰人声,时长 10s-5min(建议 15 秒),支持 wav/mp3/m4a 格式。
生成精美的播客封面图。
```python theme={null}
import requests
response = requests.post(
"https://api.minimaxi.com/v1/image_generation",
headers={
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
},
json={
"model": "image-01-live",
"prompt": image_prompt,
"aspect_ratio": "1:1",
"response_format": "url",
"style": {"style_type": "漫画", "style_weight": 1}
}
)
image_url = response.json()["data"]["image_urls"][0]
```
返回图片的 URL 有效期为 **24 小时**,请及时下载保存。
***
## 实用技巧
| 场景 | 建议 |
| ---- | --------------------------------------------------------------------------------------------------- |
| 音色试听 | 使用 [语音调试台](https://platform.minimaxi.com/examination-center/voice-experience-center/t2a_v2) 试听并选择音色 |
| 模型选择 | `speech-2.8-hd` 自然度最高;`speech-2.8-turbo` 生成速度快 |
| 语音克隆 | 上传音频时长建议 **15 秒左右**,效果更佳 |
***
## 应用拓展
支持多角色灵活对话,无固定发言顺序
加入搜索能力,提供最新消息
接入翻译能力,生成多语言版本
利用情感参数,丰富表现力
***
## 总结
本教程展示了如何使用 **MiniMax 多模态 AI 能力**构建完整的 AI 播客生成应用。通过集成文本生成、TTS 语音合成、语音克隆、文生图四大核心能力,实现了从用户输入到播客成品的全流程自动化。
开发者可以基于本项目的架构思路,将 AI 能力组合成更多创新应用。
***
## 相关资源
语音合成接口
音色克隆接口
图像生成接口